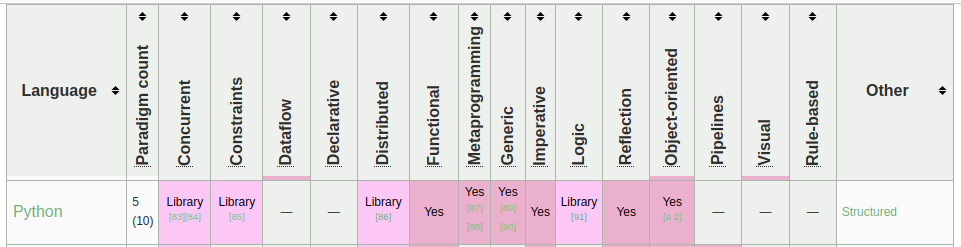
Python - supported paradigms.
- Python jest językiem wysokiego poziomu (jego syntax jest zrozumiały dla ludzi).
- Ponadto, Python jest językiem dynamicznie typowanym o silnym systemie typów.
Python - good practices.
- Czytelność vs. złożoność?
- W Pythonie zasada „Simple is better than complex” (Zen of Python) działa w 90% przypadków. Pytanie pomocnicze => Czy mogę to napisać prościej, bez utraty czytelności?
- Generator czy comprehension?
- Reguła: Jeśli nie potrzebujesz leniwego generowania → użyj comprehension.
- [Py Zen2] Updated Python Zen list.
![[Py Zen2] Updated Python Zen list.](images/Zen2_GPT.png){kind=link}
Generators.
- The truth about generators, when they are really useful and when not? How generators cooperate with Python Frame based Stack? Do Class-based Iterators use Python Frame based Stack?
- yield from ITERABLE_OBJECT
- Why and when such error happened with generators? TypeError: can't send non-None value to a just-started generator
- It occurs when you attempt to send a non-None value into a generator that has not yet been started (i.e., before its first yield statement).
- By design, the first .send(value) call must be None or the generator must be primed using next() first.
- Generatory są świetne, gdy nie znamy górnej granicy zbioru lub przetwarzamy tylko część wyników,
np. sekwencję Fibonacciego, liczby pierwsze czy duże pliki CSV linia po linii. Generatory są niepraktyczne, gdy
potrzebujemy przechowywać i przetwarzać cały zbiór naraz – np. jeśli chcemy posortować duży plik danych,
lepiej wczytać go do listy, bo generatory nie pozwalają na swobodny dostęp do elementów.
- W przeciwieństwie do zwykłych funkcji, generatory nie usuwają swojej ramki po zakończeniu wywołania yield.
Zamiast tego, stan wykonania (w tym zmienne lokalne i wskaźnik kodu) jest przechowywany w obiekcie generatora.
Mechanizm yield powoduje, że zamiast usunięcia ramki stosu (w normalnej funkcji), Python zapisuje jej stan i zawiesza wykonanie.
Kiedy generator jest wznawiany, ramka zostaje przywrócona na stos i kontynuuje działanie od miejsca yield.
- Trzy przykłady przepływów w Generatorach:
1)
* x = yield (<---)
* Ta forma oznacza "czekaj na wartość z send(value)".
coroutine zostaje uruchomiona i napotka 'x = yield', wtedy "zawiesza się" i oczekuje na dane z GEN_OBJ.send(value).
2)
* yield x (--->)
* Ta forma oznacza: Zwróć wartość x na zewnątrz — to właśnie wynik next() lub send(...)
3)
* y = yield x (<--->)
* Mix 1 i 2.
Dwa główne sposoby patrzenia na generatory?
1. Jako leniwe iteratory – najczęstszy use case: wydajne generowanie wartości w pętli (for, next()).
np. range(), open(...).readline() w tle używają mechanizmów iteracyjnych.
2. Jako prymitywy współprogramowania (coroutines)
– dzięki send() i yield można pisać funkcje, które wymieniają dane w obie strony
i przypominają prymitywną formę „asynchroniczności”.
Właśnie na tym mechanizmie oparto async/await (to tylko rozszerzona składnia do korutyn).
Ale można też dołożyć perspektywę "ramek" i tego, że generatory to nie są tylko wyjątkowe funkcje:
Na pocztku normalny obiekt funkcji kiedy się go wywoła zwraca obiekt generatora (nie generorwaną wartość od razu).
Ten obiekt generatora to właściwie "zatrzymana" ramka stosu, która może być wznowiona.
- The one benefit of yield from is to allow easy refactoring of generators.
- The second "performance optimization" is even more important. Simulation showed "yield from" speeds up execution about 10-30%.
- O tej funkcjonalności można powiedzieć sporo więcej:
-- Przykład: Rekurencyjna iteracja po strukturze drzewiastej
-- Przykład: Dwukierunkowa komunikacja z yield from
-- Python poszedł tu nieco pod prąd i dodał coś, czego brakuje w innych językach.
Można to uznać za niekonwencjonalne, ale to dobrze wpisuje się w filozofię Pythona: mniej kodu, większa czytelność.
-- Python często dodaje konstrukcje, które upraszczają kod, nawet jeśli wydają się „magiczne”.
Czasem wydaje się, że Python chce być bardziej jak DSL (Domain-Specific Language)
dla każdej możliwej sytuacji, a nie czysto „przewidywalnym” językiem ogólnego przeznaczenia.
y = yield from sub_generator()
- automatycznie iteruje przez cały sub_generator(), wszystkie yield z tamtego trafiają "na zewnątrz",
- a jeśli sub_generator() zakończy się return coś, to yield from zwraca tę wartość do y.
gen = accumulator() gen.send(10) # ❌ TypeError: can't send non-None value to a just-started generator
Python miscellaneous.
- What are main differences in Functions/Classes nature?
- It was possible to compare some very specific solutions in terms of speed (by not realistic micro-benchmarking, but at least something). First solution based on functions and second based on classes. In the result class-based solution was 100 times slower. Why classes could be so slow? What are the biggest factors here? Additionally, in tests were seen that __slot__ classes feature did not improve speed, but tests were limited so this result could be not reliable.
- Why immutable types were created in Python? There can be mentioned few reasons, but one can be that "it was needed for more complex data structures". The word about Hash maps, dictionaries, scopes/namespaces.
- What are cases in Python where internal state (implementation details) are hidden from users?
- MappingProxy / FrozenSet / NamedTuple / Arrays / Deque / SimpleNamespace - why/when these structure can be useful?
- Unicode and UTF-8 are default in Python 3, but what does it really mean?
- Python float implements IEEE 754, so float64 precision (53 bit mantis). 2**53 is the biggest number represented accurately.
- In Python str class there are maketrans (static method) and translate methods. It can be useful for converting text and removing specific symbols.
- Ellipsis it is unique constant accessed globally in Python (instance of EllipsisType). When we can use ellipsis object?
- Why Python/CPython is so slow? Many reasons? One is that PVM interprets bytecode line by line - there are no native CPU instructions (like for example in JVM).
- Running object creation in infinite loop, but without assigning to reference. Memory consumption did not increase. Garbage collector doesn't show any symptoms of working behaviour. This is edge case when Python potentially ignored such object memory allocations. But spotted possible GC related Memory leak when running object creation in infinite loop, with constantly re-assigning reference (gc_objects = gc.get_objects()). Memory consumption increases. GC tracked objects increases.
- Classes can be seen more like containers/structures/blueprint when functions are set of instructions (executable code blocks).
- A class definition is a 'Declaration of a Structure', not a sequence of instructions (like functions).
- While you can inspect the bytecode of class methods, the class object doesnt have bytecode associated to be disassembled.
* That code can be disassembled, but it's part of the higher-level object and it is not attached to the final class object
- Python classes are highly dynamic (add, remove, modify attributes at runtime). This flexibility comes at performance cost.
- Classes due protocols/hooks are very modifiable during creation time. It also costs.
Then:
- In Classes Nature is to be very modifiable containers/blueprints. When Functions Nature is to be lightweight set of instructions.
- Creating a function is a simpler operation than creating a class. Python's interpreter is optimized for function creation. - Classes, even empty ones, have more overhead due to their inherent complexity. - Class creation flow is much more complex: Metaclass handling, namespace creation or executing class body code. It all takes time.
- lru_cache / cached_property - weakref module - asyncio / threading
Unicode is universal symbol representation system
- it contains all world alphabets and also other symbols like emojis.
When UTF-8 is Unicode symbols coding system to bytes form.
UTF-8 is a variable-width encoding that supports all 1,112,064 valid Unicode code points using one to four bytes.
- UTF = Unicode Transformation Format
Unicode / UTF-8 example:
Unicode mapping:
chr(300) => Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff.
'Ĭ'
ord('Ĭ') => Return the Unicode code point for a one-character string.
300
UTF-8 encoding:
bytes('Ĭ', "UTF-8") # Zwraca bajty reprezentujące znak Ĭ w kodowaniu UTF-8.
b'\xc4\xac' # 0xC4 0xAC => 11000100 10101100 => To są 2 bajty reprezentujące znak Ĭ w UTF-8.
>>> sentence = "Ann has a great day! What about you?"
>>> sentence_output = sentence.translate(str.maketrans("!", "."))
>>> sentence_output
'Ann has a great day. What about you?
- In slicing (advanced indexing) - As a placeholder in code (“to be implemented later”) - In type hints (PEP 484 / typing) - For custom or creative uses
Python Execution model view (with importing modules system). More details attached.
- Python 'import module_A' and Python Execution model.
- In terms of module importing what happens during Parsing Stage, Compilation Time and Runtime?
- What if there is second the same import? - [import system] Python Execution Model and 'Python Startup Stage'.
- [import system] More details, parsing stage 1.
- [import system] More details, parsing stage 2 and (ast).
- [import system] '__main__.py' and runnable packages.
- [import system] Zaawansowane techniki importu, Lazy imports i optymalizacja importów (Python 3.7+)
- [Py Execution Model] Utworzenie kontekstu wykonania (execution context)
- [Py Execution Model] Bardziej dokładny model wykonania.
1. Python binary startup stage
- Uruchomienie procesu/programu CPython w OS (np. Linuxie)
- sprawdzenie/pobranie zmiennych środowiskowych i przełączników (PYTHONPATH, "-i", itd)
- import modułów wewnętrznych (wkompilowanych w binarkę CPython-a, ale też Frozen modułów)
2. Parsing phase (kod źródłowy Pythona -> obiekt/drzewo AST)
- Co tutaj się dzieje?
Najpierw wykonywane jest parsowanie "python code" na części zwykle nazywane tokenami. (Tokenizer/tokenizer.c)
...
Ostatecznie, finalna AST struktura jest generowana
- Komponenty fazy parsowania: Tokenizer / Lexer, Parser
- Najpierw Python czyta kod źródłowy uruchamianego / głównego pliku np 'script.py'
(na tym etapie nawet jeśli istnieje aktualny bytecode / plik .pyc to nie jest brany pod uwagę).
- Na tym etapie nie wykonuje 'import module_A' tzn NIE wczytuje module_A.py i nawet nie sprawdza, czy ten plik istnieje.
Tj. domyślne zachowanie w CPython, ale przy innych implementach lub bardziej skomplikowanych importach może być inaczej.
- Linia import module_A po prostu zostaje zapisana w AST (potem bytecode) jako instrukcja do późniejszego wykonania.
- Podsumowując, na tym etapie Python NIE parsuje kodu module_A.py podczas parsowania script.py.
Parsowanie każdego modułu dzieje się dopiero, gdy interpreter faktycznie wykona instrukcję import w czasie Runtime.
2. Compilation phase
- Import nie jest wykonywany podczas kompilacji script.py — tylko zostaje przygotowany do wykonania.
Python traktuje import module_A jak zwykłą instrukcję.
W AST jest reprezentowana jako np. 'ast.Import'.
W bytecode pojawi się instrukcja typu IMPORT_NAME.
3. Execution context preparation
module Frame, frame links, globals, locals, Python stack
namespace model (LEGB) — to logiczna część kontekstu
4. Runtime
- Gdy interpreter napotyka instrukcję 'import module_A', to wtedy jest wykonywana pełna obsługa importu modułu module_A.
Jej przebieg:
Runtime(import flow 1) - Python sprawdza sys.modules czy dany moduł jest już załadowany
(Nie jest.)
Runtime(import flow 2) - Python szuka module_A.py w sys.path
(Jeśli plik 'module_A.py' istnieje a .pyc jest nieaktualny lub brak.)
Runtime(import flow 3) - Python wczytuje źródło 'module_A.py', sprawdza składnię kodu i parsuje go do AST,
Runtime(import flow 4) - Następnie Python kompiluje kod do bytecode`u.
Runtime(import flow 5) - Teraz Python:
Tworzy obiekt modułu (types.ModuleType)
Rejestruje go w sys.modules
Runtime(import flow 6) - W końcu Python wykonuje bytecode w namespace modułu.
To tak naprawdę uruchomienie wszystkiego, co nie jest ukryte w funkcji lub klasie.
Krok po kroku:
6a)
Wykonywany jest cały tzw. kod na poziomie globalnym modułu
definicje klas i funkcji
przypisania zmiennych
instrukcje warunkowe, pętle
dowolny kod imperatywny
blok if __name__ == "__main__" jest ignorowany, nigdy warunek nie będzie spełniony
6b)
To działanie (6a) ma konkretne efekty strukturalne w Pythonie:
Tworzy się przestrzeń nazw (namespace) modułu
Wszystko, co zostanie zdefiniowane (funkcje, klasy, zmienne), trafia do mod.__dict__.
To właśnie ta przestrzeń jest potem dostępna jako module_A.some_function.
Tworzone są obiekty klas i funkcji
Podczas wykonywania def i class tworzony jest odpowiedni obiekt typu function lub type.
Każdy def to instancja function, a class to wywołanie metaklasy.
Wszystkie efekty uboczne się wykonują
Jeśli w module jest np. print("Uruchamiam się!"), to ten print się wykona.
Jeśli jest połączenie z bazą danych — ono też może się wykonać (jeśli umieszczone globalnie).
Importy zależne też są wykonywane
Jeśli module_A importuje inne moduły (import module_B), to zaczyna się kaskada importów.
Other things: importlib.reload()
- Python re-executes the module (skipping parsing/compiling if bytecode is cached and valid).
- All top-level code runs again, which can reset state or redefine classes/functions.
import importlib
importlib.reload(module_A)
![[import system] Python Execution Model and 'Python Startup Stage'.](images/import_system_details_pl.png){kind=link}
![[import system] More details, parsing stage 1.](images/import_system_MoreDetails_ParsingStage1_pl.png){kind=link}
![[import system] More details, parsing stage 2 and (ast).](images/import_system_MoreDetails_ParsingStage2_pl.png){kind=link}
![[import system] '__main__.py' and runnable packages.](images/import_system__mainDotPy_file.png){kind=link}
![[import system] Zaawansowane techniki importu, Lazy imports i optymalizacja importów (Python 3.7+)](images/import_system_AdvancedTechnics_LazyImports_optimization.png){kind=link}
![[Py Execution Model] Utworzenie kontekstu wykonania (execution context)](images/execution_context.png){kind=link}
![[Py Execution Model] Bardziej dokładny model wykonania.](images/PyExe_advanced.png){kind=link}
Python Call Stack / Python Frames.
- Cases when Python creates Frames objects?
- functions calls, - importing modules, - execution main script (__main__), - execution classes call body. - also, eval/exec calls can cause additional Frames are created.
CLASSES
- Weak references, unpopular Python feature (class __weakref__ attribute that does almost nothing. Weak references logic is managed by Python interpreter). Advanced projects with critically important memory management aspect (for example: help for Garbage Collector).
- Python class level '__slots__' mechanism - it predefines possible instance attributes (there is no __dict__ on instance level). Many instance as performance optimization Use Case. Simulation showed 150-300 MB memory saving when 1 million objects are handled.
- dir() - there is easy explanation why dir command does not return always all attributes. Simply, it calls __dir__ underneath and __dir__ can be implemented differently. And often it is. Python documentation says "The default dir() mechanism behaves differently with different types of objects, as it attempts to produce the most relevant, rather than complete ..."
- When obj = object() then obj is instance of class (named object), but object is class and classes are instances of type metaclass (unless you use your own new metaclass). In Python everything inherits from object class apart from type metaclass that doesn't inherit from anything.
- Python 3.7 introduced a concept known as "forward references," which allows us to use the class name as a string when defining type hints. Starting from Python 3.7, you can also use the from __future__ import annotations import, which automatically treats all annotations as forward references.
- '__subclasshook__' - interesting feature that allows to dynamically deduct if subclass belong to base class (even without real inheritance).
- What does mean that super technically can be called "proxy object"? What are details of functioning super?
- super only redirects lookup-calls to the correct parent class.
- For this super uses Descriptor protocol - it has own implementation of __get__.
- super handles creating temporary binding objects for instance and class methods (this binding is only relevant for the duration of the method call).
- Bound methods. Base Concept for different type of functions in Class definitions. For example, @staticmethod decorator role is to revert/bypass this machinery.
- What are details about class creation flow/protocol in Python? How can it be tuned?
- What it is zero-cost metaclassing mechanism?
- Implementing metaclass __call__ method causes that this method is called during class instance creation (flow is changed).
- The word about 'object' class - concretely instances - and when object() structure could be useful. object() doesnt have __dict__ and is immutable. (Sentinel, Locks)
- PEP 697, Python 3.12 introduces a zero-cost mechanism that optimizes the way metaclasses are determined.
PROTOCOLS (Descriptors, Attribute lookup)
- Python as protocol oriented language. There is set of behaviours implemented as Protocols in Python, but to be Protocol oriented language? It is probably not enough.
- [Protokół Deskryptorów]: Python Deskryptor obiekt - to jest Pythonowy obiekt, który implementuje Protokół Deskryptorów i jest przy okazji atrybutem klasowym innej klasy (kontekst).
- Obiekt ten (Python Deskryptor obiekt) może posiadać różnoraką implementację jego dynamicznych zdolności zdolności, ale wymaga implementacji przynajmniej '__get__'.
- Gdy Deskryptor implementuje tylko "__get__" to mówimy o Non-Data Descriptorze.
- Gdy Deskryptor implementuje "__get__" i "__set__/__delete__" to mówimy o Data Descriptorze.
- Python jest głęboko związany z Desktryptorami (fe: functions, methods, properties, class methods, static methods, super).
- The mechanizm deskryptorów jest schowany w __getattribute__ methodach (object, type, and super). Dodatkowo __getattr__ jest użyty, gdy atrybut/deskryptor rzuca AtributeError wyjątkiem.
- __set_name__ hook jest wołany podczas "tworzenia obiektu klasy" i rozszerza możliwości deskryptorów.
- [Attribute lookup protocol]: Attribute lookup for Class, Instance, Super:
In high level it is such mechanism:
try:
[type, object, super].__getattribute__(...)
except AttributeError:
[type, object, super].__getattr__(...)
Potential modifiers:
- Descriptors, Metaclasses, __slots__
- re-writing: __getattribute__, __getattr__, AttributeError
Use cases (different __getattribute__):
1. Instance objects - lookup for instance attribute - lookup for class attribute - object.__getattribute__ |
2. Class objects: - lookup for class attribute - type.__getattribute__ |
3. Super object executes lookup:
- by default super().__getattribute__ is taken
|
Other things:
- it can be said that module objects use Attribute Lookup protocol too
- Summary: Why Attribute Lookup is needed for Python?
Functions Deep Dive
- Functions are objects, but not so-typical. What makes functions not typical objects?
- Tricky edge case for imports in Class when code is C-based. How creating Bound Method works here?
1. Functions local scope is built different:
- Function local scope exists in runtime and is built based on temporarily created Stack Frame,
- this Frame leverages the data from funct.__code__ for creating local scope
- If we have look into temporarily created Frame (named F) then:
- we can check that: F.f_locals is locals() => gives True
- so Python Frame Stack is used to build Function local scope
2. Functions have a __code__ object storing function bytecode.
3. Functions have a __dict__ used bit different, only for storing attributes (what is kind of specific functions behaviour).
4. Functions support closure pattern (__closure__ remembers variables from outer scope). Fundamental mechanism for predictability.
5. Every function written in Python is Non-Data Descriptor (when C based not).
class A:
from json import dumps as g # written in Python and defines __get__ (however there can be 2 implementations: Python/C)
from itertools import repeat as h # it is callable class written in C, doesn't define __get__
Notes:
* During Runtime when 'class A' is created, class body-content is being executed line by line (like function).
* A.g("xx") - ok
* A.h("xx") - ok
* A().g("xx") - TypeError: dumps() takes 1 positional argument but 2 were given
* A().h("xx") - ok
* @classmethod impact
Testing things:
Testing things:- Mock and Stub what is the difference? Other test doubles: Dummy, Fake, Spy
- Mocking frameworks: unittest.mock, when to use MagicMock and when Mock?.
- Mocking vs patching? What is difference?
Mock:
- It should be used for verifying interactions, ensuring the correct methods are called with the expected parameters.
- Mocks can be configured to throw exceptions, return different values for different calls, and so on (can be complex).
Stub:
- this test double focuses on providing data (predefined responses) to control the test environment
- often used to simulate the behavior of external services or components (isolating dependencies)
=> Both stubs and mocks help isolate the code under test by replacing external dependencies with controlled behavior.
Dummy
- the simplest form of a test double. It is an object that is passed around but is never actually used (serves as a placeholder)
- Dummies are used when an argument is required by the code being tested, but it’s not actually used during the test.
Fake
- test double that has working implementations but is simplified or not as performant as the real system
- Fakes are used when a real system might be too complex or slow, but you still want some kind of working implementation
Spy
- more advanced type of test double that not only helps verify interactions (like a mock) but also records the calls made to it
Fixture
- In the context of testing, fixtures can be considered as part of the broader test double or test setup family.
- Any setup or configuration required to run your tests. Ensuring that the necessary context is available for the tests to execute.
- Typically includes the creation of test data, that can be even related to setting up a connection to a database or web server.
- Fixtures are about test setup and teardown — while test doubles isolate/control behavior of components within that environment.
Test Doubles (Mocks, Stubs, Fakes, etc.):
- Used to replace or simulate specific parts of a system, like dependencies or external services, that your code interacts with.
- They help isolate/control the code under test and allow you to control behaviors and verify interactions.
Use Mock when: - You only need to mock regular methods or attributes that are not related to magic methods (i.e., methods you define yourself). - You don't need support for special behavior like indexing, iterating, or arithmetic operations. Use MagicMock when: - You need to mock magic methods (__getitem__, __setitem__, __call__, __iter__, etc.) or objects involved in such operations. - You deal with objects that emulate builtin containers like lists, or objects that need to support special methods in your tests.
Concurrency things:
- When 'race condition' situation happens?
- What means that operations are 'thread-safe'?
- multiple threads or processes access shared data and at least one modifies it, but the access is not properly synchronized.
- ensuring that only one thread can modify 'specific shared resource' at a time.
TODO:
- fastapi, pydantic - Django simple personal website - Bigger project ideas
Python Data Model / Python Data Types.
Python Data Model: - wewnętrzna architektura i zestaw zasad określających, jak obiekty w Pythonie zachowują się i współdziałają ze sobą. Python, rodzaje typów danych: - typy proste - typy sekwencyjne - typy zbiorów - typy słownikowo-mapujące - typy binarne - typy funkcjonalne i użytkownika
Iterators, Iterables, Sequences.
- Iterator and Iterable objects implementing certain protocols. What are details of these protocols?
- What are builtin Iterable data structures that are also Iterators (have __next__ and __iter__)?
- What are details of sequence protocol in Python?
Iterator protocol: - Iterator object needs to implement __iter__ and __next__. Main feature of Iterators is allowing for sequence access of data stream - no need to maintain all data in memory. Iterable protocol: - Iterable object should implement __iter__, but not it is not requirement if there is no __iter__ then __getitem__ is required. In the other words iter(Iterable_object) should always produce valid Iterator object. Also, there are 2 different contracts about Iterator/Iterable protocols: 1. Iterable Always, when Client calls 'iter()' I will give "new iterator" object. 2. Iterator I am Iterator already, I maintain state - dont copy me.
[!!!] __getitem__ edge case: - Still it is possible to create a class that have only __getitem__ and not __iter__ and such object will be Iterable. - It is rather hack than common practice, but handling __getitem__ in Iterable protocol still works.
- map, filter, reduce, zip - map example:
>>> L = [0, 2, 4, 6, 8]
>>>
>>> mapped_L = map(lambda x: x + 1, L)
>>>
>>> mapped_L
map object at 0x70d609f84a60
>>>
>>> hasattr(mapped_L, "__iter__")
True
>>> hasattr(mapped_L, "__next__")
True
>>> hasattr(mapped_L, "__getitem__")
False
=> map objects are Iterables and Iterators (but not Sequences)
Sequence objects in the most basic version need to implement two dunder methods: __getitem__, __len__:
- __getitem__, __len__ are base for Indexing and slicing functionalities.
- __getitem__ from dict doesnt allow Indexing and Slicing, so having __getitem__ is not enough, implementation matters.
- In more complete version also methods: __contains__, __iter__, __reversed__, index and count.
All Sequences are also Iterable, but not opposite.
Range object example:
>>> R = range(3)
>>> type(R) #
<class 'range'>
>>> hasattr(R, "__getitem__")
True
>>> hasattr(R, "__len__")
True
>>> R[1]
1
>>> hasattr(R, "__iter__")
True
>>> hasattr(R, "__next__")
False
=> range objects are Sequences and Iterables, but not Iterators
import this # PEP 20, Zen of Python
Narzędzia lintujące (wymuszają dobre praktyki):
flake8 — sprawdzanie zgodności ze stylem PEP8
black — automatyczne formatowanie kodu
(według standardu)
pylint — bardziej szczegółowa analiza
jakości kodu
mypy — sprawdzanie poprawności typów
Zalecenia:
1. Stosuj PEP 8, PEP 20
2. Czytelność ważniejsza niż spryt
3. Używaj typów i adnotacji
4. List/dict/set comprehensions
zamiast pętli budujących listy
5. Enumerate zamiast ręcznego licznika
6. Zip do łączenia list
7. Unpacking
8. Context manager (with)
zamiast ręcznego otwierania/zamykania
9. Małe, czytelne funkcje –
każda powinna robić jedną rzecz.
10. Docstringi, PEP-257
11. „DRY” – don’t repeat yourself.
12. Testy jednostkowe
(moduł unittest/pytest).
13. Zasada EAFP:
„Easier to Ask for Forgiveness than
Permission”
14. Zasada SOLID